AWS ma przyjemność zaprosić na 5-dniowy AWS Pop-up Hub, który odbędzie się w Warszawie 10-14 października.
Otrzymasz szansę uczestniczenia w ponad 20 sesjach, ponad 6 warsztatach projektowych, Szkoleniach i Laboratoriach Certyfikacyjnych oraz w indywidualnych spotkaniach z naszymi ekspertami.
Temat: How to transform a notebook model into a system pipeline
Opis prelekcji: “In the world of data analysis, there is a lot of information on the Internet about building models of various kinds to solve all kinds of problems. However, when a complex model is developed, it is necessary to implement it in a software system.
In this step, most of the people dedicated to data science, need the help of software architects and engineers, MLOps, etc. Therefore, in this workshop, we intend to show the first steps to identify how to segment a model in processing stages, and implement a distributed pipeline, managed by basic continuous integration techniques, allowing the creation and maintenance of a comprehensive system that serves the model.
To do so, we will first introduce the concept of microservice architectures and event-driven architectures, and then explain what an event broker is and start working with a real one, Apache Kafka.
Once the work base is established, we will teach how to create microservices in Python integrated with Apache Kafka, with a model (or part of it) integrated in these, as well as the necessary scripts for the continuous integration of these.
Finally, we will explain the possibilities offered when integrating ingest, storage, etc. so that attendees can expand their knowledge in this area later.”
Prelekcja w języku angielskim.
Serdecznie zapraszamy – spotkanie otwarte dla wszystkich zainteresowanych!
Opis prelekcji: „Legal research is a highly manual and time-consuming process. Legal professionals, for example, have to read court cases that are up to 100 pages long, just to identify the most important aspects in order to decide whether their firm should represent the case.
Natural Language Processing (NLP) techniques like information extraction and summarisation thus provide great opportunities to save law firms time. However, applying NLP to legal documents is highly challenging due to the domain-specific terminology and variability in the legal document layout.
In this talk, we show how Thomson Reuters Labs tackles these challenges and present our work on summarising court cases and providing human-understandable explanations thereof.”
Opis prelekcji: „The increasing use of algorithmic decision-making technologies (colloquially referred to as “AI”) in industry, commerce and public service provision are giving rise to concerns about potential negative impacts on individuals (e.g. algorithmic discrimination bias) and the wider socio-economic fabric of society (e.g. displacement of jobs).
With trust in the technology being cited as a key barrier for successful deployment, both in the public and private sector, there is a growing push toward translating AI ethics principles into actionable practice.
This talk will review current initiatives towards the development of AI governance frameworks, ethics and oversight related standards and regulations, and discuss the role each of these can play within a wider ecosystem of trustworthiness for the use of AI.”
Wszystkich zainteresowanych – prosimy o wcześniejszą rejestrację (bardzo to pomoże w organizacji wydarzenia!): https://forms.office.com/r/GHhsDehQwy
Parę słów na temat prelekcji:
„Od 8 lat firma OKE Software realizuje własne projekty B+R w zakresie inteligentnej analizy obrazu i dźwięku.
Jednym z ostatnich projektów opartym na sztucznej inteligencji jest system automatycznego monitoringu miejskiego.
Podczas prezentacji opowiemy jak problemy z danymi i adnotacjami dały początek idei systemu wspomagającego adnotacje i wersjonowanie modeli, który aktualnie tworzymy.
Przedstawimy jedno z podejść do wybierania obserwacji reprezentatywnych w uczeniu aktywnym – Bayesowską sieć neuronową.„
Po prelekcji przewidziany jest poczęstunek i czas na networking.
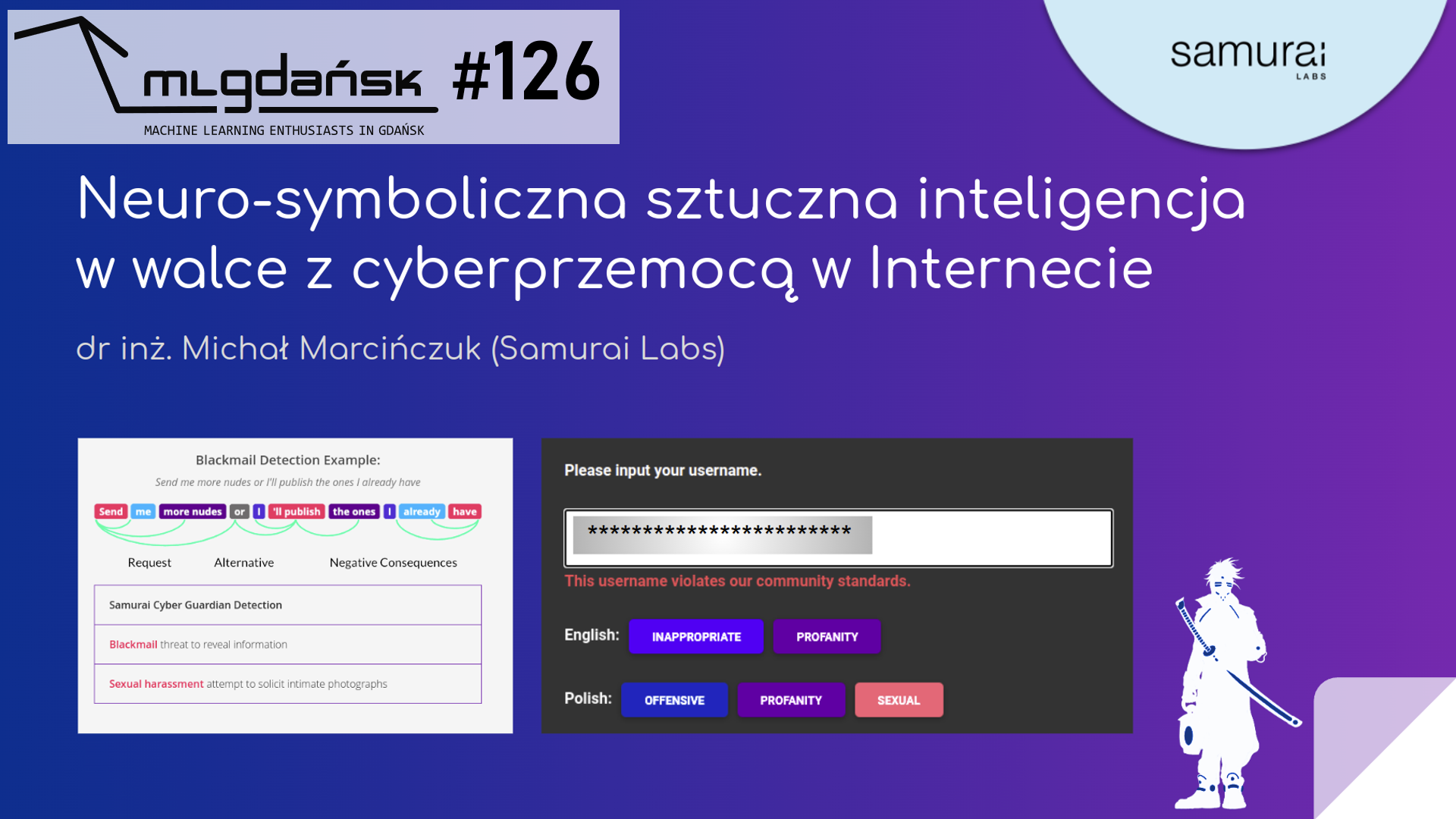
„Samurai Labs specjalizuje się w tworzeniu technologii informatycznych do walki z cyberprzemocą w Internecie.
Nasze główne obszary zainteresowania to przetwarzanie tekstu w celu wykrywania ataków personalnych, mowy nienawiści, treści suicydalnych, pedofilii.
Nasze zadania realizujemy poprzez łączenie metod symbolicznych oraz metod maszynowego uczenia.
Podczas prezentacji przedstawimy w jaki sposób wykorzystujemy uczenie maszynowe do wspomagania modeli symbolicznych w zadaniach charakteryzujących się niską frekwencja wykrywanych zjawisk.”
Tematem prelekcji to: Metody efektywnego zarządzania i deploymentu systemów opartych o deep learning
Parę słów od Prelegenta:
„Zarządzanie skomplikowanymi procesami machine learning, szczególnie w większej skali, wymaga zbioru wyspecjalizowanych narzędzi pokrywających różne etapy tych procesów.
Elastyczna parametryzacja pipeline’ów, experiment tracking i proste kolejkowanie zadań to kluczowe elementy umożliwiające łatwe zarządzanie tego rodzaju procesami.
Na podstawie doświadczeń z ReSpo.Vision, opowiemy o narzędziach, które stworzyliśmy i wybraliśmy, by możliwie łatwo zarządzać systemem do ekstrakcji danych 3D z nagrań wydarzeń sportowych – mając do dyspozycji widok tylko z jednej kamery.
System zbudowany jest w oparciu o modele deep learning oraz machine learning, których jakość przewidywań jest od siebie bezpośrednio zależna. Przedstawię również możliwości, które otwiera dodanie warstwy 3D do analityki sportowej.”
Tematem prelekcji to: Co myślimy o szczepieniach przeciwko COVID-19?
Opis prelekcji:
„Wciąż jest wiele osób, które wahają się, czy należy się zaszczepić, czy nie, mimo że osiągnięcie odporności stadnej jest kluczowym elementem zakończenia pandemii COVID-19.
W dużym stopniu wpływ na nich mają opinie zamieszczane w mediach społecznościowych, m.in. na Twitterze.
Autorzy zaprezentują wyniki badań nad analizą sentymentu opartych na polskim korpusie danych z Twittera.
Pozwala to lepiej zrozumieć stosunek społeczeństwa do COVID-19 i szczepień przeciwko COVID-19.”
Politechnika Gdańska uruchamia program wspierania Startupów.
Zachęcamy do wzięcia udziałów zainteresowanych. Poniżej informacja od organizatorów tego programu.
„Uruchomiony został program Molybdenum Startup School, którego celem jest zbudowanie trwałego, systemowego mechanizmu inicjowania i wspierania rozwoju przedsiębiorczości akademickiej.
Osią programu Molybdenum, realizowanego w projekcie pod nazwą Szkoły Startup, są dwa cyklicznie wznawiane programy startupowe:
1. warsztatowo-szkoleniowy program Startup School I „Sprawdź swój pomysł”,
2. program grantowy Startup School II „Rozwiń skrzydła”.
Zespoły biorące udział w tych programach mogą składać się z dowolnej konfiguracji studentów, doktorantów, pracowników, a także absolwentów PG.
Pod pewnymi warunkami członkami zespołów mogą zostać również studenci, doktoranci lub pracownicy innych uczelni wchodzących w skład Związku im. Daniela Fahrenheita, a w uzasadnionych przypadkach również osoby spoza tej grupy.
Okoliczność ta stwarza doskonałą okazję do budowania zespołów o szerokich, uzupełniających się, interdyscyplinarnych kompetencjach.
Aktualnie rozpoczynamy nabór do 1. edycji programu „Sprawdź swój pomysł”. Osoby zainteresowane uczestnictwem zapraszamy do zapoznania się z dokumentacją konkursową oraz do przesłania wniosku o udział w programie w terminie do 27. marca br.
Zachęcamy jednocześnie do odwiedzin strony Szkoły Startup, na której zamieściliśmy szereg dodatkowych informacji, w tym harmonogram programu Startup School I „Sprawdź swój pomysł” oraz opis zaplanowanych zajęć.
Niezależnie od aktualnego naboru zachęcamy wszystkie osoby zainteresowane przedsiębiorczością startupową do rejestracji w naszym serwisie. Pozwoli to Państwu być na bieżąco z informacjami o wydarzeniach organizowanych przez Szkołę Startup, w tym o kolejnych naborach do programów Startup School I i II oraz przyszłych warsztatach, szkoleniach i webinariach.
Tematem prelekcji to: Predicting the Unpredictable: Mathematical Models and the Covid 19 Pandemic
Opis prelekcji:
„Predicting the future of the COVID-19 pandemic is a challenging task and can not be done without mathematical models describing the progression of the epidemic.
Despite large uncertainties about epidemiological relevant medical and social key parameters, mathematical models can provide deep insights into the dependency of the epidemic dynamics on those parameters.
Epidemiological models can furthermore be used to develop and improve rational strategies for controlling the COVID-19 epidemics.
We focus in the talk on fundamental mathematical features of individual based epidemic models and highlight the close relation to problems in percolation and random graph theory.
We emphasize the special role of households and discuss some results and conjectures in first passage percolation and their impact on epidemic processes.
Finally we present some outcomes of the MOCOS microsimulation model for the COVID -19 epidemic in Poland and Germany and reflect on problems related to model based policy advice for epidemic control.”